OddGridBench: Exposing the Lack of Fine-Grained Visual Discrepancy Sensitivity in Multimodal Large Language Models
CVPR 2026
OddGridBench -- Characteristics
- OddGridBench is a benchmark designed to evaluate the fine-grained visual discrepancy perception ability of MLLMs.

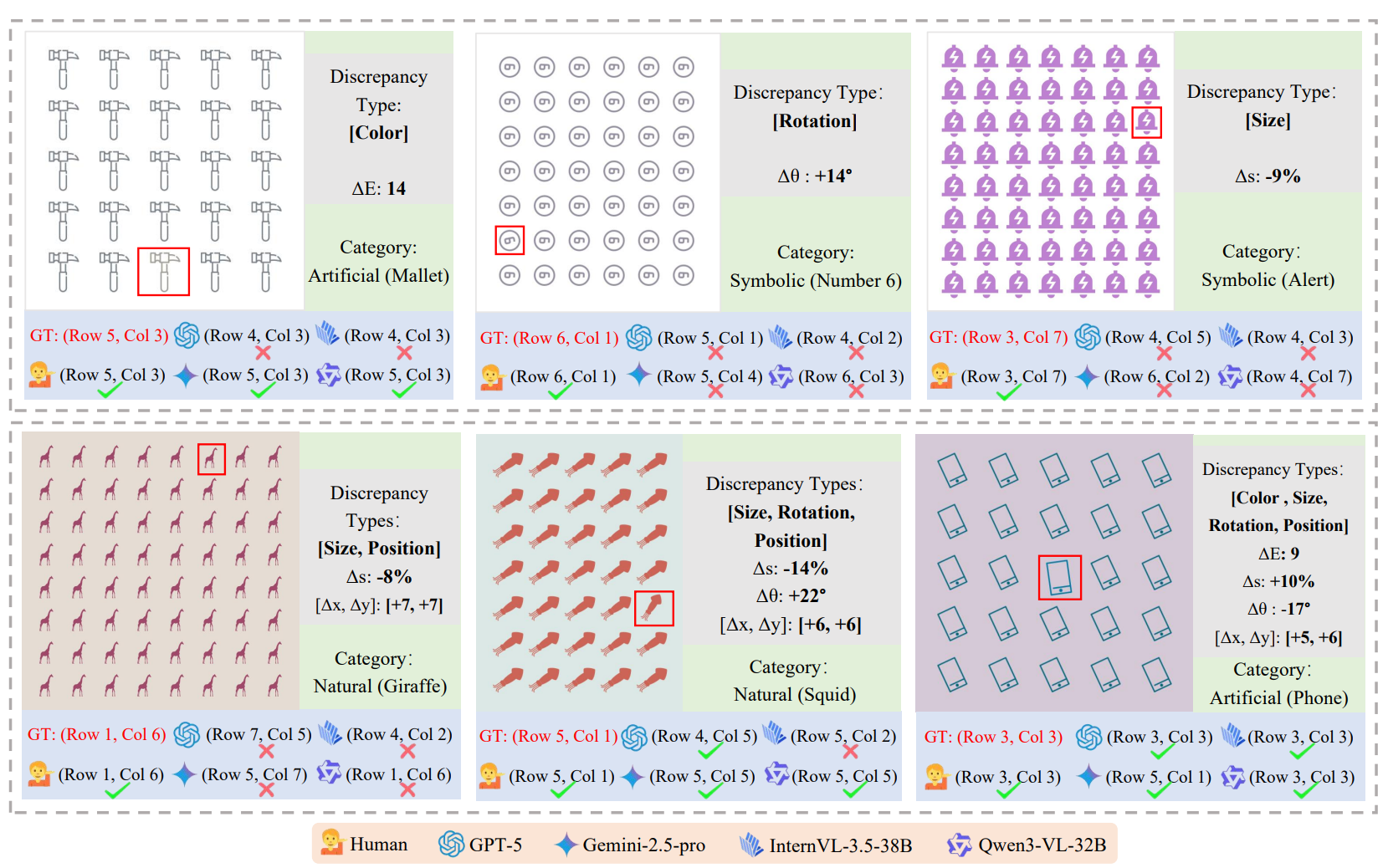
Illustration of discrepancy perception: identifying odd items that deviate from the majority pattern in a grid of similar objects.
- OddGridBench presents a set of visually similar items arranged in a grid, where most items follow a consistent pattern and only a small number are anomalous. These anomalies may differ in attributes such as color, shape, orientation, size, or texture. While humans can easily detect such discrepancies through visual comparison, current MLLMs still struggle with these fine-grained perceptual distinctions.
Dataset Construction

OddGridBench is constructed through a controllable generation pipeline. We first collect large-scale SVG icons from multiple sources, including manually selected icons from IconFont and training icons from Material Design Icons. A Python program then generates grid-based images by randomly sampling controllable parameters such as grid size, block size, and icon category. To create anomaly instances, we inject discrepancies into specific positions by modifying visual attributes such as color, size, rotation, or spatial position. This procedure enables the large-scale generation of diverse grid layouts with precisely controlled anomaly types and locations, forming the final OddGridBench dataset.
Methodology (OddGrid-GRPO)

We introduce OddGrid-GRPO, a reinforcement learning framework designed to improve the visual discrepancy perception ability of MLLMs. First, the training set is automatically scored according to difficulty based on controllable visual attributes such as color difference, size variation, rotation angle, and positional offsets. The dataset is then partitioned into easy, medium, and hard subsets. During training, we adopt a curriculum-guided optimization strategy that gradually introduces harder samples, enabling the model to progressively learn fine-grained visual comparison. In addition, we propose a distance-aware reward mechanism within the GRPO framework, which provides partial rewards based on the spatial distance between predicted and ground-truth anomaly locations. This encourages more precise localization of discrepancies and stabilizes policy optimization.
Results

We evaluate 19 representative Multimodal Large Language Models (MLLMs), covering both open-source and proprietary systems, on OddGridBench. The benchmark measures the ability of models to detect visual discrepancies across multiple attribute types, including color, size, rotation, and spatial position. As shown in the results, most current MLLMs struggle to reliably identify anomalous items within structured grids. Even the strongest open-source model, Qwen3-VL-32B, achieves only 68.07% overall accuracy, which remains substantially below human performance (87.47%). These results reveal that fine-grained discrepancy perception remains a significant challenge for current multimodal models.
Example Samples









BibTeX
@inproceedings{weng2026oddgridbench, title={OddGridBench: Exposing the Lack of Fine-Grained Visual Discrepancy Sensitivity in Multimodal Large Language Models}, author={Weng, Tengjin and Jiang, Wenhao and Wang, Jingyi and Li, Ming and Ma, Lin and Ming, Zhong}, booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2026} }